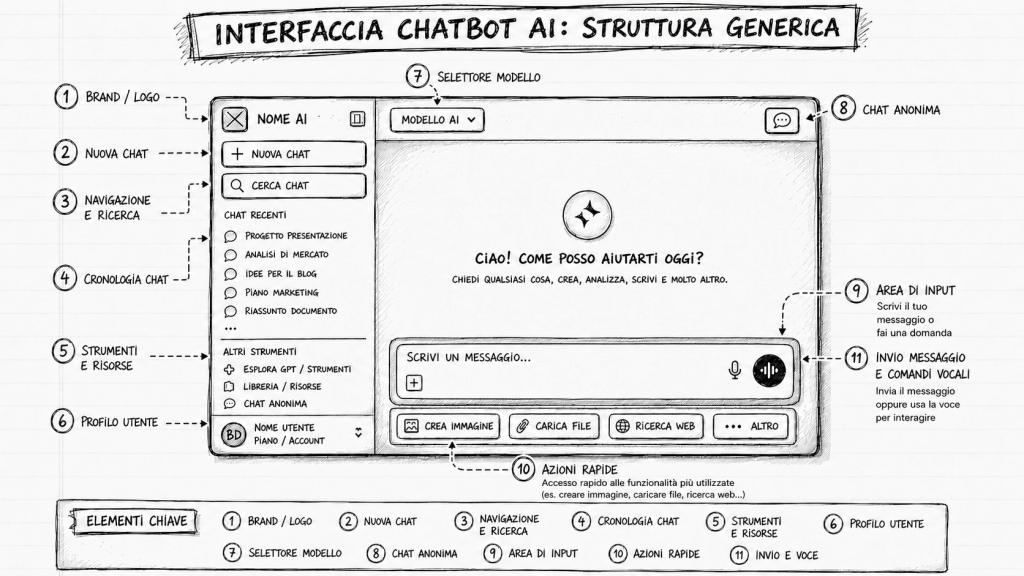
A volte non ci rendiamo conto di quanto velocemente si stia evolvendo l’AI generativa.
Stavo preparando, con l’aiuto di ChatGPT, questa immagine da utilizzare in uno dei miei prossimi corsi (la troverete utile sicuramente, che siate formatori i “studenti”), e mi sono accorto che aveva erroneamente collocato nell’angolo in alto a destra l’icona dell’ingranaggio e la voce IMPOSTAZIONI.
Gli ho segnalato l’errore, e l’ha corretto, ma non mi sarei meravigliato nel veder cambiare l’icona e il testo corrispondenti. Mi sono meravigliato, invece, notando che ha corretto anche l’elenco in basso, di conseguenza, senza che io glie l’avessi chiesto (ero già pronto a dover ripetere l’operazione per essermene dimenticato).
Ah, se vi state chiedendo come ho ottenuto lo schema presente nell’immagine, ve lo riassumo dicendovi che gli ho fatto analizzare tre schermate di altrettanti chatbot (ChatGPT, Gemini e Claude) chiedendogli di cogliere gli elementi comuni e di inserirli in una immagine nelle posizioni corrispondenti, aggiungendo il testo esplicativo. Dopo avere ottenuto una prima versione stile “wireframe”, gli ho chiesto di applicare lo stile grafico che uso di solito per le mie slide (e che ho usato negli ultimi libri) e di cui tengo sempre a portata di mano la descrizione in inglese.
Quasi quasi faccio il test con il nuovo Gemini per vedere cosa succede…