Oggi vi lascio un prompt con cui potete ottenere delle vere e proprie infografiche stile “enciclopedia” con il nuovo modello grafico di ChatGPT, Images 2.0.
Sostituite semplicemente l’argomento fra parentesi quadre con quello che desiderate, e ammirate il risultato (vi lascio alcuni esempi dopo il prompt):
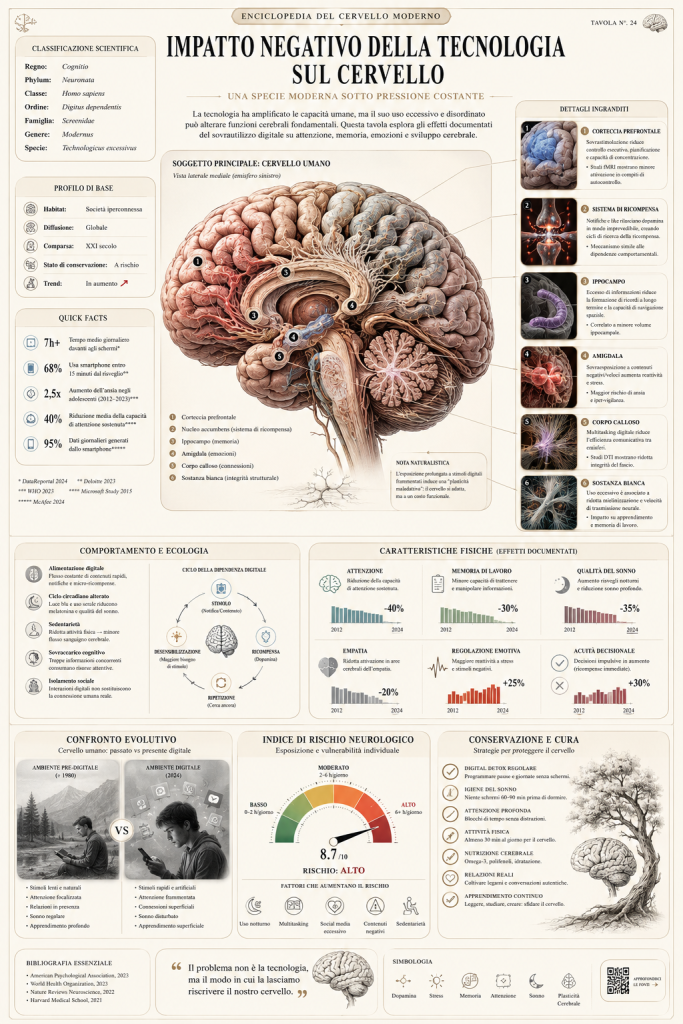
Crea un'infografica verticale premium in stile "enciclopedico" su [ARGOMENTO], con l'aspetto di una pagina tratta da un manuale di storia naturale da collezione, fusa con l'estetica del moderno infographic design editoriale. Il layout deve risultare fortemente strutturato, didattico e modulare — non un poster pubblicitario né un manifesto promozionale.
Includi: un'immagine principale grande e ultra-dettagliata del soggetto; più riquadri di zoom su dettagli specifici con callout; pannelli informativi con angoli arrotondati; sezioni dedicate a tassonomia e profilo essenziale; schede su comportamento ed ecologia; caratteristiche fisiche; curiosità rapide; moduli di confronto; sistemi di valutazione a icone; grafici sintetici; testo in stile enciclopedico conciso e preciso.
Sul piano visivo: sfondo chiaro e neutro; palette cromatica sobria e raffinata con ombre leggere; tipografia elegante; piccole icone scientifiche; spaziatura editoriale curata. L'insieme deve combinare alta densità informativa con piena leggibilità.
Il risultato finale deve somigliare a una scheda di riferimento pubblicabile — della qualità di un pannello museale — progettata per essere collezionata e condivisa sui social media.Ecco, infine, alcuni esempi: