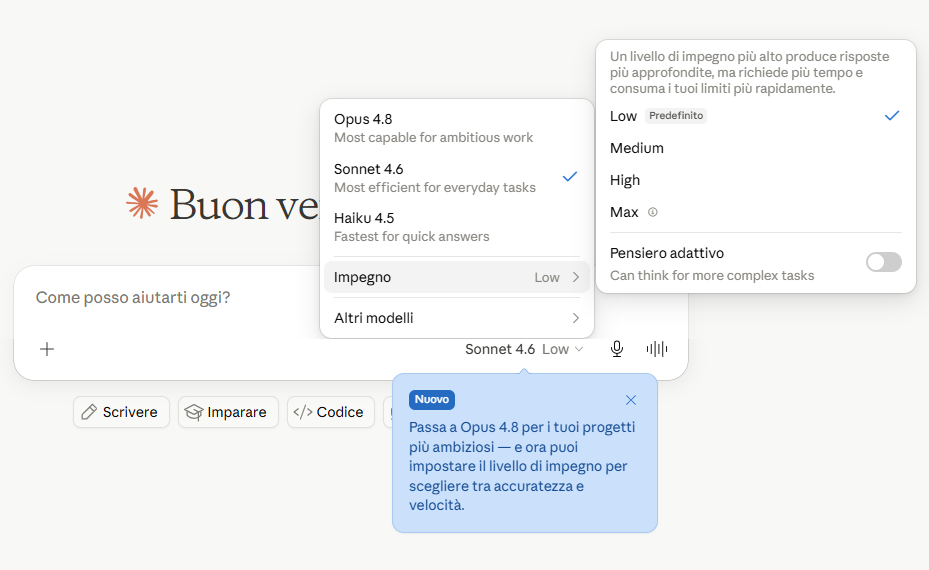
Non solo nei modelli, anche nella loro “calibrazione”.
L’arrivo del nuovo Opus 4.8 si affianca alle quattro opzioni di “potenza” utilizzabili anche per il modello intermedio Sonnet (vedi screenshot).
Fate solo attenzione tanto a selezionare quanto a calibrare il modello a seconda dei task da eseguire, perché i limiti di utilizzo si raggiungono sempre più facilmente.
A proposito del nuovo Opus, ecco cosa dice Anthropic nel suo comunicato ufficiale (sotto trovate il link):
“Uno dei miglioramenti più evidenti dell’Opus 4.8 è la sua onestà. Addestriamo tutti i nostri modelli a essere onesti — ad esempio, per evitare affermazioni che non possono sostenere. Ma un problema generale dei modelli di IA è che a volte saltano a conclusioni affrettate, affermando con sicurezza di aver fatto progressi nel loro lavoro nonostante le prove siano scarse. I primi tester riportano che Opus 4.8 è più propenso a segnalare incertezze sul suo lavoro e meno a fare affermazioni non supportate. Ciò è confermato dalle nostre valutazioni, che mostrano che Opus 4.8 è circa quattro volte meno propenso rispetto al suo predecessore a permettere che difetti nel codice scritto passino inosservati.“
https://www.anthropic.com/news/claude-opus-4-8